
01. Intelligent Towing Tank (Paper 01, Paper 02, Demonstration Code)
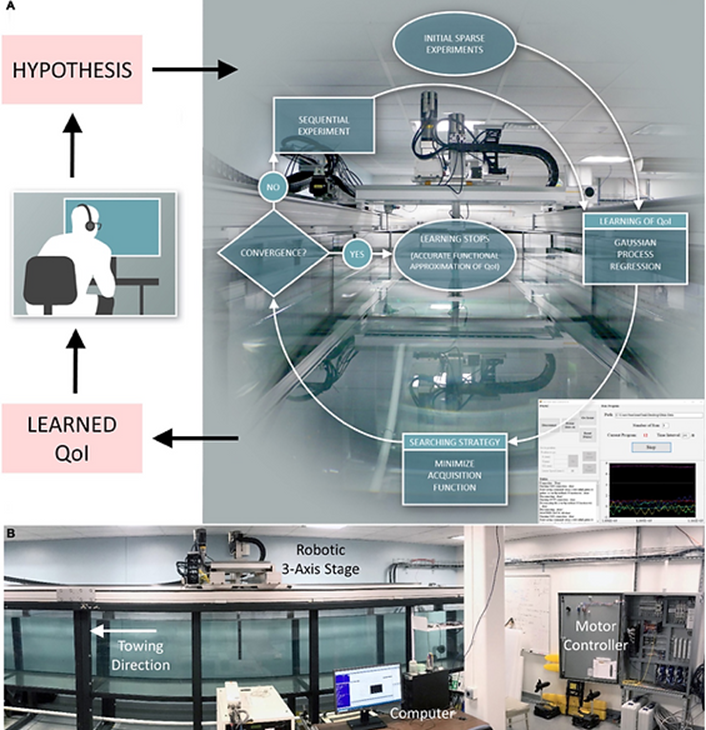
I designed and constructed the ITT, shown in Fig. 01.
The process of the ITT is as follows:
· A hypothesis is proposed (such a hypothesis is human-generated, or, in the future,
may be synthe sized in coordination by robots, computers and humans [1]).
· The ITT performs the adaptive sequential experiment to learn target quantities of
interests (QoIs), interrupted only by pause periods between experiments to avoid
cross-contamination of the results between successive experiments.
· Upon convergence, the results of learned QoIs are further post-processed to examine
the validity of the hypothesis. During sequential experimental testing, there is no
human-in-the-loop.
The learning algorithm running on the ITT is Gaussian process regression (GPR). The
input for the next experiment in sequence is decided by maximizing the standard
deviation, quantified uncertainty by the GPR.
We let the ITT study one of the canonical FSI problems: the hydrodynamic forces of a
rigid cylinder undergoing vortex-induced vibrations (VIVs). A very nice demonstration of
the phenomenon can be found here by Dr. Gabe Weymouth.
Fig. 01, Schematic image of the ITT
Example 01: A demonstration of ITT learning process on the lift coefficient in phase with the velocity (Clv) of a rigid cylinder only vibrating in the cross-flow direction, shown in Fig. 02. (Publication)
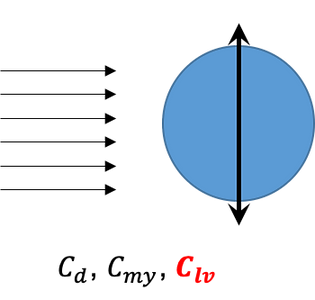
Fig. 02, A rigid cylinder forced to vibrating in the uniform inflow
Example 02: The Reynolds number effect on the CF-only oscillating cylinder. (Preprint)
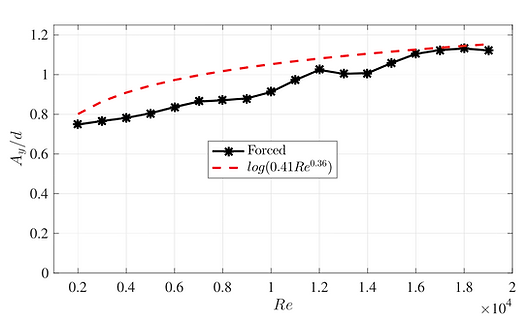
Fig. 03, Comparison between the predicted CF amplitude for a zero-damped cylinder from the forced (current) and free vibrations [2]
02. Physical-Informed Reinforcement Learning on Flow Control
Deep Reinforcement Learning (DRL) holds considerable promise for motion control of robots with complex dynamics and in unstructured environments. We developed a simulation platform to model the fish-like swimming in complex flow environments. The platform is composed of two main parts: a fluid solver based on an immersed boundary—lattice Boltzmann method (IB-LBM) and a motion control algorithm based on physics-informed reinforcement learning (PIRL). The PIRL agent can sense the state of the environment and take actions to affect it. The IB-LBM accepts the action, evolves the environment and stores the data in the replay memory pool, which will be used by the PIRL agent to optimize the control policy (Fig. 01). This platform could be a useful starting point for the development of an accurate, robust and self-adaptive motion control algorithm, which can be subsequently transferred to a robotic fish in a realistic environment. The utility of the platform is illustrated in classical swimming problems such as vortical navigation (Mov. 01) and collective swimming (Mov. 02).
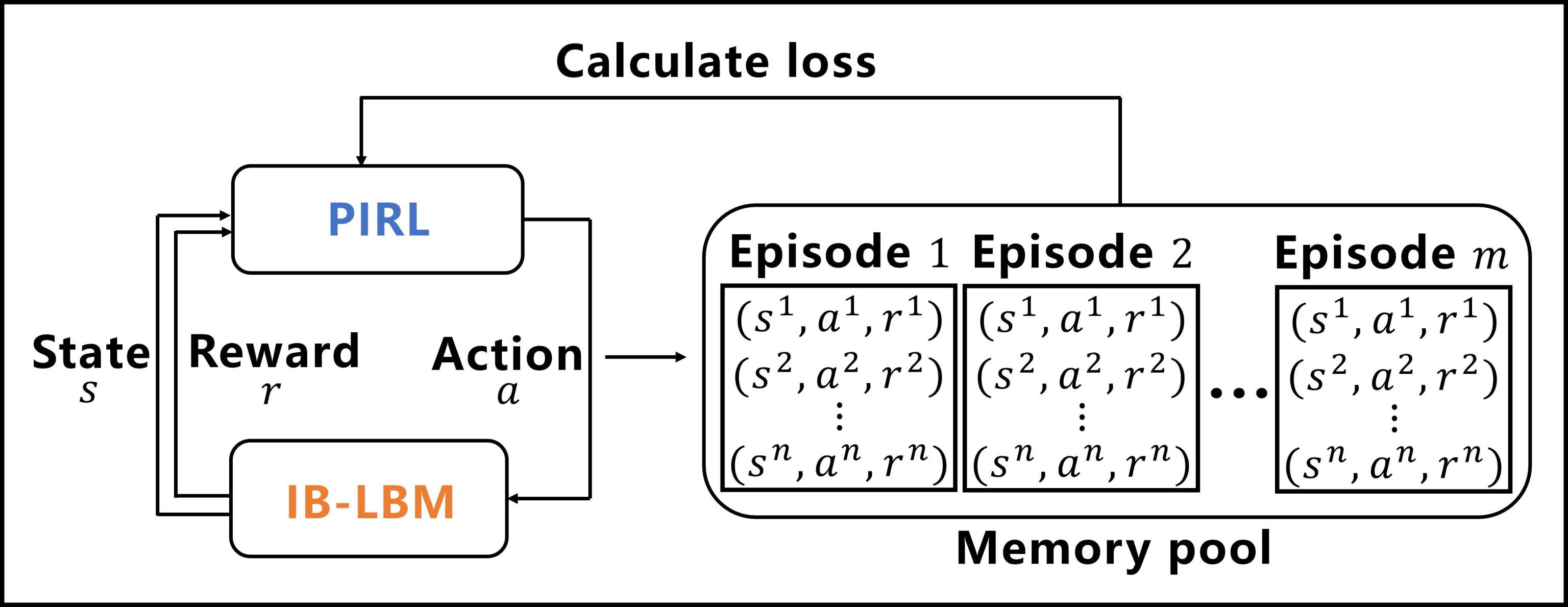
Fig. 01 A framework of the agent-environment interaction.
Mov. 01 A smart fish swims in a vortex street. Mov. 02 Two smart fish swim collectively.
03. System Parameter Estimation using PINN (Ongoing)
[1] J. Wise, These robots are learning to conduct their own science experiments. Bloomberg Businessweek. (April 11, 2018).
[2] R. N. Govardhan, C. H. K. Williamson, Defining the ‘modified Griffin plot’ in vortex-induced vibration: revealing the effect of Reynolds number using controlled damping. J. Fluid. Mech. 561, 147-180 (2006).

